Ô tìm kiếm trông rất đơn giản cho tới khi người dùng hỏi bằng những từ không hề có trong tài liệu. Họ viết: “Nếu gói dịch vụ tự gia hạn nhầm, tôi có lấy lại tiền được không?” Trang chính sách lại nói về refund, thời hạn hủy, điều chỉnh hóa đơn và điều kiện áp dụng. Cách tìm theo từ khóa cho kết quả rất kém vì chữ không khớp. Người đọc thì hiểu ngay hai bên đang nói cùng một chuyện. Hệ thống cần cách tìm theo nghĩa, không chỉ dò đúng mặt chữ.
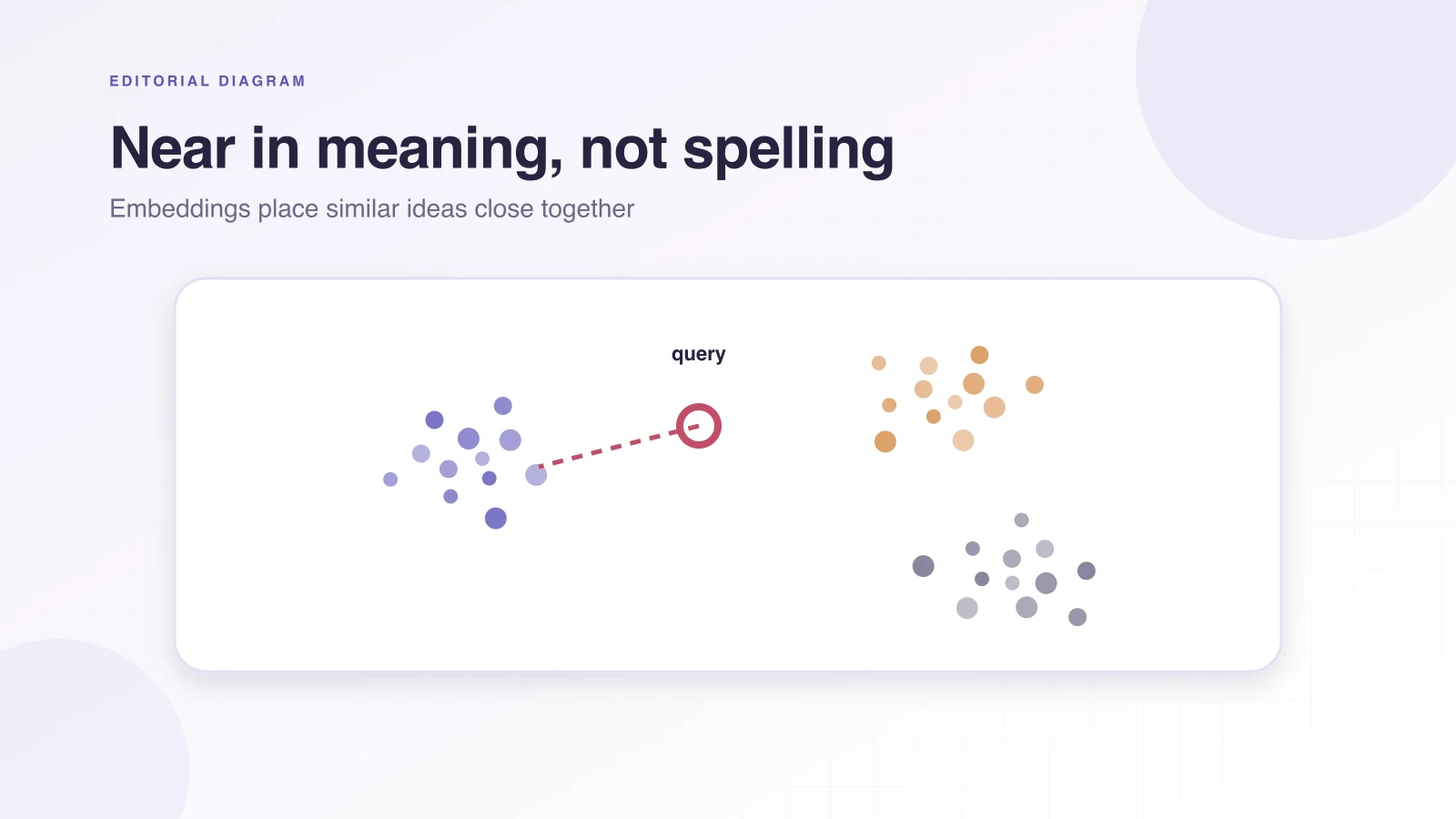
Đó là lý do rất đời khiến vector database trở nên quan trọng trong sản phẩm AI. Vector là một dãy số dùng để biểu diễn một thứ gì đó, thường là đoạn văn, hình ảnh, âm thanh hoặc code. Mô hình embedding biến nội dung gốc thành dãy số ấy. Nội dung có ý nghĩa gần nhau được kỳ vọng nằm gần nhau trong không gian vector. Các con số không dành cho con người đọc; chúng là tọa độ để máy so sánh mức độ tương đồng ở quy mô lớn.
Vector database lưu những embedding đó và tối ưu việc tìm hàng xóm gần nhất. Khi người dùng đặt câu hỏi, hệ thống cũng biến câu hỏi thành vector, rồi tìm những vector nằm gần nó. Các kết quả gần nhất có khả năng mang nội dung liên quan dù không lặp lại đúng từ. Nhờ vậy, câu hỏi “lấy lại tiền” vẫn có thể dẫn tới tài liệu dùng từ “refund”.
Tuy nhiên, database không hiểu ý nghĩa như con người. Nó chỉ so khoảng cách toán học giữa các embedding. Phân biệt này rất quan trọng. Vector search hữu dụng vì mô hình embedding đã học được nhiều mẫu trong ngôn ngữ và dữ liệu, chứ database không có óc phán đoán. Nó tìm được đoạn có liên quan nhưng không bảo đảm đoạn đó đúng, còn hiệu lực hay đã đầy đủ.
Vector database thường nằm trong hệ thống RAG. Thay vì để LLM trả lời chỉ từ những gì mô hình đã học, sản phẩm truy xuất các đoạn liên quan từ kho tri thức rồi đưa chúng vào ngữ cảnh. Mô hình viết câu trả lời dựa trên phần vừa lấy được. Một thiết kế tử tế cho người dùng xem nguồn và biết từ chối trả lời khi ngữ cảnh quá yếu, thay vì lấp chỗ trống bằng một câu nghe hợp lý.
Chunking là một trong những quyết định thực tế đầu tiên. Chunk quá lớn kéo về cả một đoạn dài với nhiều chi tiết thừa. Chunk quá nhỏ lại cắt mất bối cảnh cần để hiểu đúng. Cách chia tốt nên đi theo cấu trúc nội dung: tiêu đề, đoạn văn, bảng, code block, ngày tháng và nơi sở hữu. Công việc này ít bắt mắt hơn chọn database, nhưng nhiều khi ảnh hưởng chất lượng truy xuất mạnh hơn.
Metadata là hàng rào giúp vector search dùng được trong sản phẩm thật. Tài liệu có thể gắn locale, phiên bản sản phẩm, mức truy cập, phòng ban, ngày, người phụ trách và trạng thái. Chỉ dựa vào độ tương đồng, hệ thống dễ lấy trúng một tài liệu nghe rất hợp nhưng đã cũ hoặc người dùng không có quyền xem. Bộ lọc metadata thu hẹp việc tìm kiếm vào đúng biên: chỉ tài liệu công khai, chỉ chính sách hiện hành, chỉ tenant này, đúng ngôn ngữ và đúng quyền truy cập.
Độ mới của dữ liệu là một vấn đề âm thầm khác. Tài liệu thay đổi, chính sách hết hạn, code snippet chuyển chỗ. Nếu nguồn đổi mà embedding không đổi theo, vector database sẽ giữ ký ức của một tổ chức trong quá khứ. Hệ thống nghiêm túc cần quy trình nạp dữ liệu, cách re-embed, đường xóa dữ liệu và khả năng lần một câu trả lời về đúng phiên bản nguồn đã tạo ra nó.

Evaluation là bước biến bản demo thành sản phẩm có thể tin. Đội ngũ nên gom câu hỏi thật cùng tài liệu nguồn kỳ vọng, rồi đo xem hệ thống có kéo đúng nội dung lên không. Cảm giác “demo chạy ổn” là chưa đủ. Cần nhìn recall, precision, latency, chi phí, cách hệ thống từ chối và tần suất người dùng mở nguồn. Vector database có thể làm ô tìm kiếm trông thông minh hơn; chỉ đánh giá lặp lại mới cho biết nó có giúp công việc thật hay không.
Đánh đổi về chi phí và chất lượng cũng luôn có. Approximate nearest neighbor index cho tốc độ tốt nhưng đôi lúc bỏ lỡ kết quả phù hợp nhất. Vector nhiều chiều có thể giữ tín hiệu phong phú hơn, đổi lại tốn dung lượng lưu trữ và tài nguyên tính toán. Trong nhiều sản phẩm, hybrid search kết hợp keyword với vector mạnh hơn việc chỉ chọn một bên. Câu trả lời thường là semantic search đi cùng metadata, đối sánh từ khóa, quy tắc xếp hạng và cách hiển thị nguồn mà con người đọc được.

Tôi hình dung vector database như một giá sách xếp theo độ gần về nghĩa. Nó mạnh khi người dùng không biết chính xác từ cần gõ, khi nhiều tài liệu diễn đạt cùng một ý theo những cách khác nhau, hoặc khi tính năng AI cần ngữ cảnh có nguồn. Nhưng đây không phải “bộ nhớ thần kỳ”. Chất lượng vẫn phụ thuộc vào tài liệu gốc, mô hình embedding, cách chia chunk, bộ lọc, phép đánh giá và sự trung thực của giao diện khi đưa bằng chứng ra trước người dùng.
Nếu đang xây AI search hoặc RAG, câu hỏi đầu tiên chưa nên là vector database nào đang được nhắc nhiều nhất. Hãy hỏi người dùng thật sự cần tìm gì, việc tìm kiếm phải tôn trọng những ranh giới nào, và bằng cách nào ta biết kết quả truy xuất đã đúng. Database quan trọng; kỷ luật xung quanh nó mới khiến câu trả lời đáng tin.