Demo vừa xong, một product manager quay sang hỏi: “Có nên fine-tune model không?” Assistant dùng sai giọng, bỏ sót một điều trong policy, rồi tự đẻ ra một field không hề có trong CRM. Cả bàn lập tức nêu tên giải pháp. Người bảo sửa prompt, người nói làm RAG, người muốn fine-tuning. Ba lỗi khác nhau bị gom lại rồi đổ lên đầu cùng một model.
Prompting, RAG và fine-tuning thường được đặt cạnh nhau như ba món để chọn một. Thực ra chúng đụng vào ba phần khác nhau của hệ thống. Prompting thay đổi chỉ dẫn và ngữ cảnh được gửi kèm mỗi lượt gọi. RAG tìm thêm thông tin rồi đưa vào trước khi model trả lời. Fine-tuning dùng các ví dụ để điều chỉnh cách model phản hồi. Muốn chọn đúng, trước hết phải biết mình đang thiếu gì: lời giao việc rõ ràng, kiến thức mới và riêng của tổ chức, hay một cách phản hồi cần lặp lại ổn định.

Prompting thường là chỗ nên thử đầu tiên vì nhanh, rẻ và dễ quay lại. Một prompt tử tế nói rõ yêu cầu, người đọc, giọng, định dạng, giới hạn, ví dụ và trường hợp nên từ chối. Assistant viết quá suồng sã thì mô tả giọng cần dùng và cho hai mẫu. JSON lúc được lúc không thì đưa schema cùng một đầu ra hợp lệ. Câu trả lời hay vượt ngoài quy định thì buộc nó chỉ dùng ngữ cảnh đã cấp và nói thẳng khi thiếu căn cứ. Đây không phải bước nghịch thử cho vui; nó là cách gọn nhất để hiểu sản phẩm thật sự đang đòi hỏi điều gì.
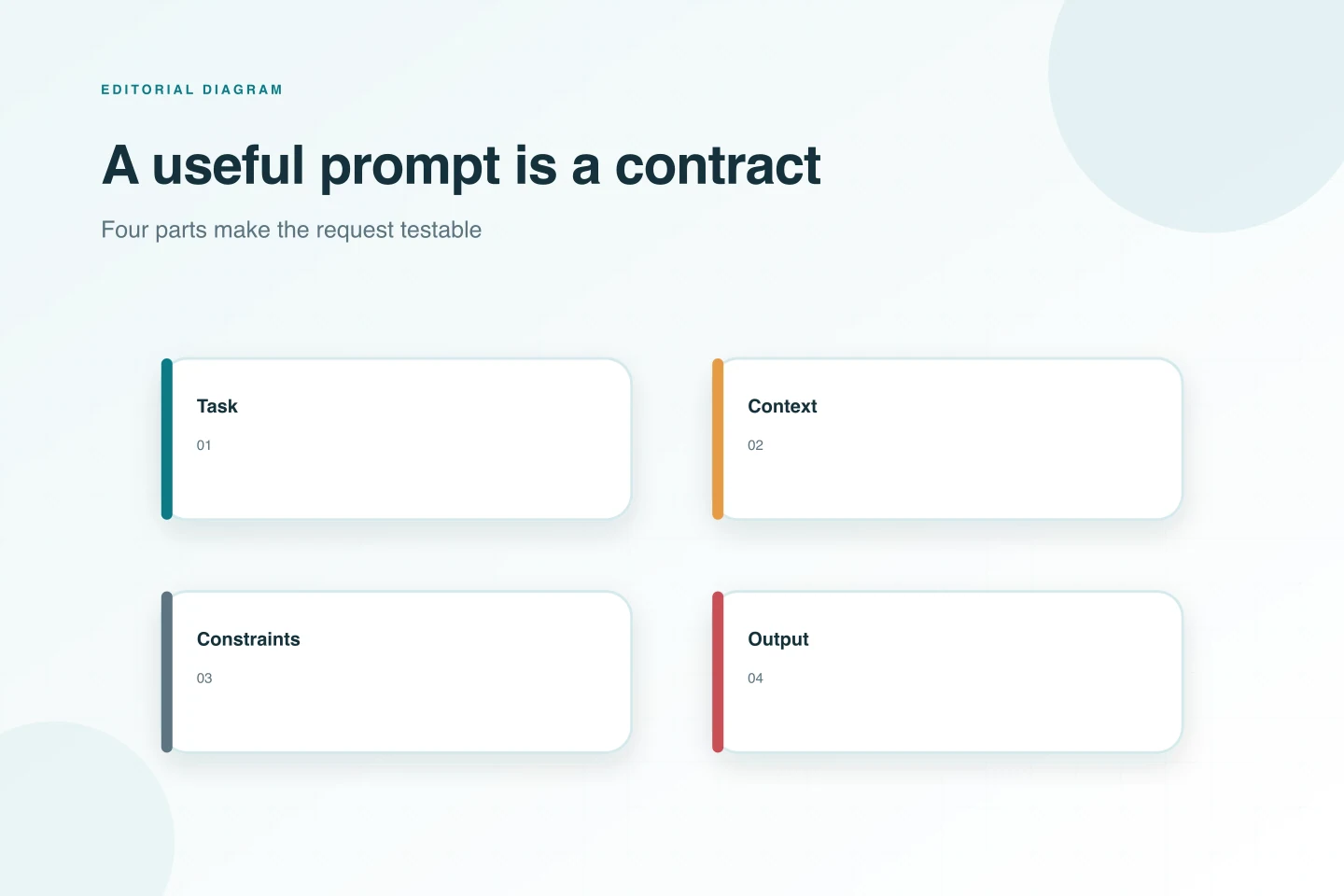
Nhưng prompt không thể tạo ra kiến thức đáng tin từ khoảng trống. Bạn có thể nhắc model làm theo quy định hoàn tiền, nhưng nó không biết bản quy định mới nhất nếu chưa được cung cấp. Bạn có thể yêu cầu dùng đúng trường dữ liệu trong database, nhưng schema đổi hằng tuần thì danh sách trường phải đến từ nguồn còn hiện hành. Khi câu hỏi phụ thuộc vào tài liệu nội bộ, quy tắc sản phẩm, lịch sử hỗ trợ hoặc trích dẫn, chỉ chăm chút câu chữ trong prompt là chưa đủ.
Đó là đất của RAG, viết tắt của Retrieval-Augmented Generation. Hệ thống tìm trong nguồn đáng tin, lấy những đoạn liên quan rồi mới nhờ model soạn câu trả lời. Cách này hợp với docs, ticket, knowledge base, runbook, release note hay code snippet do nhóm quản lý. Model vẫn phụ trách diễn đạt, còn căn cứ đến từ bước truy xuất. Nhờ vậy, câu trả lời có thể kèm trích dẫn, kiểm tra độ mới và cho người dùng thấy nó dựa vào đâu.
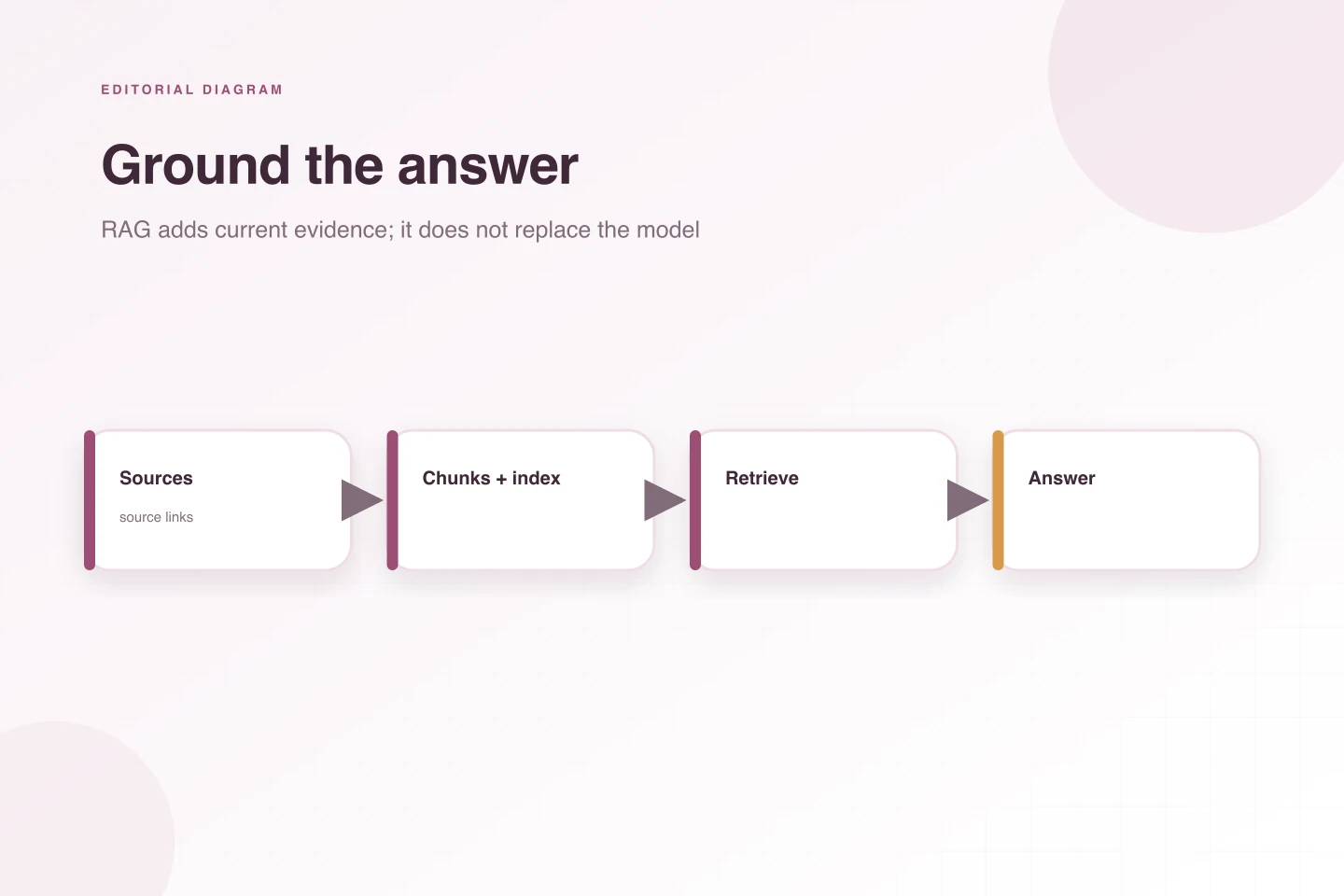
RAG cũng có cách hỏng riêng. Nó có thể lấy sai đoạn, bỏ qua tài liệu đúng, lôi về bản đã cũ hoặc mang tới hai nguồn mâu thuẫn. Model lại có thể không dùng hết ngữ cảnh vừa tìm được. Vì vậy nâng chất lượng RAG phần lớn là sửa những việc ít hào nhoáng: ai chịu trách nhiệm cho tài liệu, chia đoạn ra sao, metadata có đủ không, quyền truy cập được giữ thế nào, bộ đánh giá gồm gì và pipeline có đủ tín hiệu để theo dõi không. Kho tri thức đang bừa thì RAG không tự biến nó thành ngăn nắp; nhiều khi nó chỉ phơi cái bừa ra rõ hơn.
Fine-tuning hợp hơn khi bài toán nằm ở một khuôn mẫu lặp lại. Sản phẩm có thể cần kiểu phân loại rất riêng, một định dạng trích xuất ổn định, cách viết lại theo lĩnh vực, hoặc giọng trả lời hỗ trợ mà prompt dài vẫn giữ không đều ở quy mô lớn. Với dữ liệu mẫu tốt, fine-tuning có thể rút ngắn prompt và làm một bài toán hẹp trở nên nhất quán hơn.
Điều nó không nên gánh là dữ kiện thường xuyên thay đổi. Đưa bảng giá cập nhật mỗi tháng vào dữ liệu huấn luyện tức là đặt kiến thức sai chỗ: model nhanh chóng lỗi thời, rồi nhóm phải chạy thêm một vòng huấn luyện cho thứ lẽ ra chỉ cần cập nhật dữ liệu. Fine-tuning còn kéo theo việc chuẩn bị dataset, đánh giá, versioning và rollback. Dataset kém không chỉ giữ lại lỗi cũ; nó còn dạy model lặp lỗi ấy với giọng rất chắc chắn.
Có thể dùng một lối chọn khá thẳng. Model chưa hiểu phải làm gì thì sửa prompt. Model thiếu kiến thức nội bộ hoặc mới nhất thì dùng RAG. Prompt đã rõ, ngữ cảnh đã đúng mà model vẫn không giữ được giọng hay cấu trúc cần thiết thì mới cân nhắc fine-tuning. Hệ thống thực tế có thể dùng cả ba: prompt giao việc, RAG cấp căn cứ, model đã tune xử lý ổn định một yêu cầu hẹp. Không cần trung thành với một phe; chỉ cần chọn can thiệp nhỏ nhất đủ làm sản phẩm đáng tin hơn.
Bộ đánh giá giúp cuộc chọn lựa bớt dựa vào cảm giác. Trước khi thay đổi, hãy gom một bộ dữ liệu đầu vào thật cùng kết quả mong đợi. Gắn nhãn xem từng lỗi đến từ chỉ dẫn, truy xuất hay cách phản hồi. Sau mỗi lần sửa, chạy lại đúng bộ đó. Việc đơn giản này ngăn nhóm fine-tune để chữa tài liệu thiếu, hoặc dựng cả vector database chỉ vì prompt đang mơ hồ.
Chi phí cũng phải tính đủ. Prompting tốn công thử nghiệm và token. RAG tốn indexing, phân quyền, chất lượng retrieval và bảo trì kho kiến thức. Fine-tuning tốn dataset, training, monitoring và quản lý vòng đời model. API call có thể trông gọn, nhưng phần vận hành phía sau thì không. Cách phù hợp là cách có chi phí tương xứng với giá trị và rủi ro của tính năng.
Vậy câu hỏi hữu ích không phải “prompting, RAG hay fine-tuning cái nào mạnh nhất?” mà là “hệ thống đang hỏng theo kiểu nào?”. Chưa hiểu việc, thiếu căn cứ, hay chưa giữ được cách phản hồi? Khi lỗi đã có tên, giải pháp sẽ bớt thời thượng và thực tế hơn. Khoảnh khắc có ích nhất thường không phải lúc một hướng “thắng”, mà là lúc cả nhóm nhận ra trước đó mình đã gọi sai vấn đề.